- October 2021
- August 2021
- June 2021
- May 2021
- February 2021
Performance BugPublished by Mark Wylde on 2021-06-05
For the last few months Puzed, which uses Canhazdb, has been slowing down as time passes. This bug would cause an instance to crash at least once a day.
I had tried on and off to debug this over the past six months, but my focus was mainly on the Puzed project. This is because Puzed has so much logic, scheduled jobs, healthchecks and more. I was certain there was a leak somewhere in that code.
But as I mentioned in my previous blog post, I wanted to stress test Canhazdb on it's own to see what it's limitations are.
Starting on Puzed, I added some metrics monitoring to the project. This resulted in the following:
1) Puzed Performance
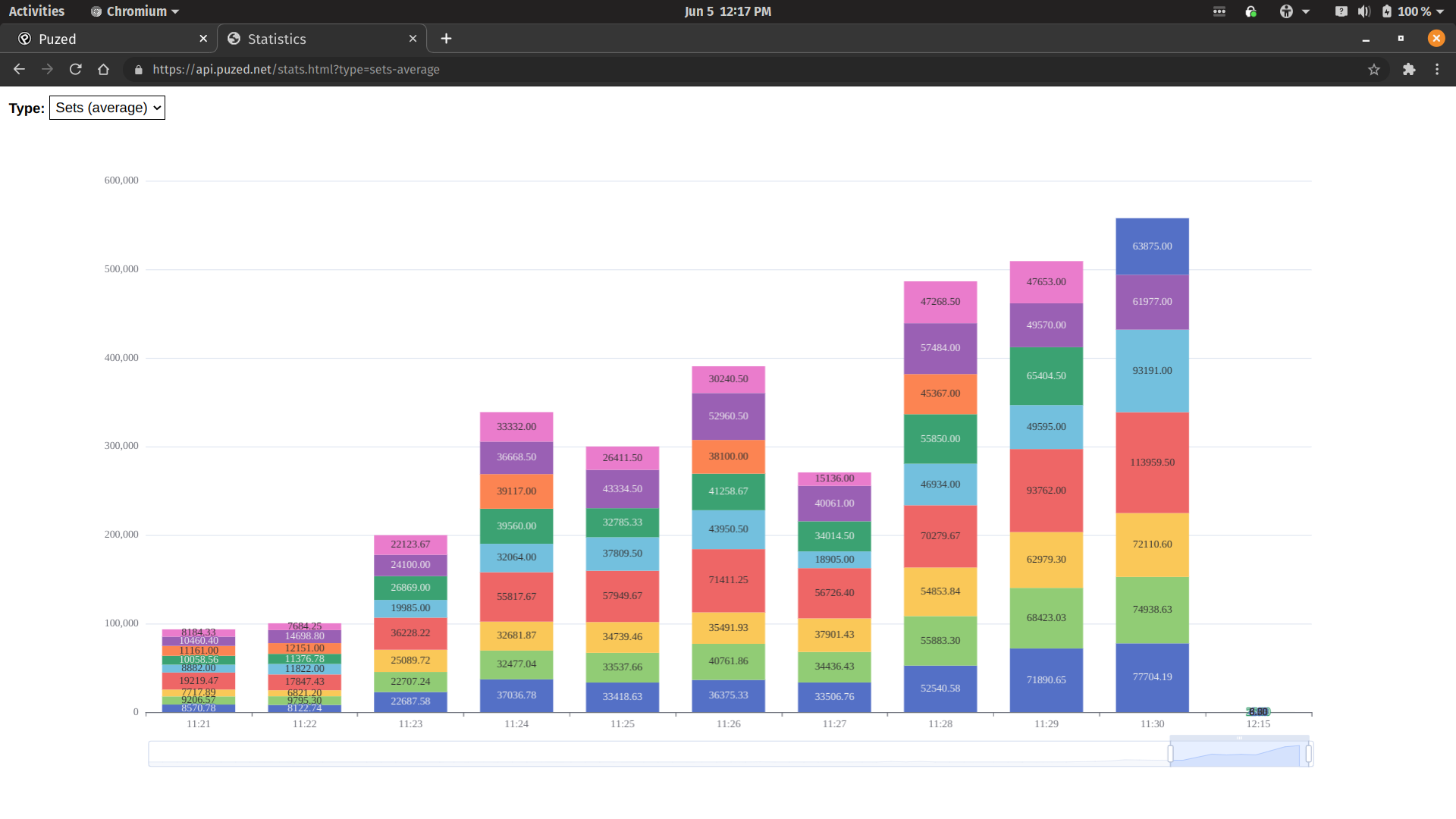
The above is a snapshot showing the different type of database requests, along with the average time (in milliseconds) it took to complete the request.
You can see, it gradually takes longer and longer to perform essentially the same number of queries.
2) Canhazdb Performance
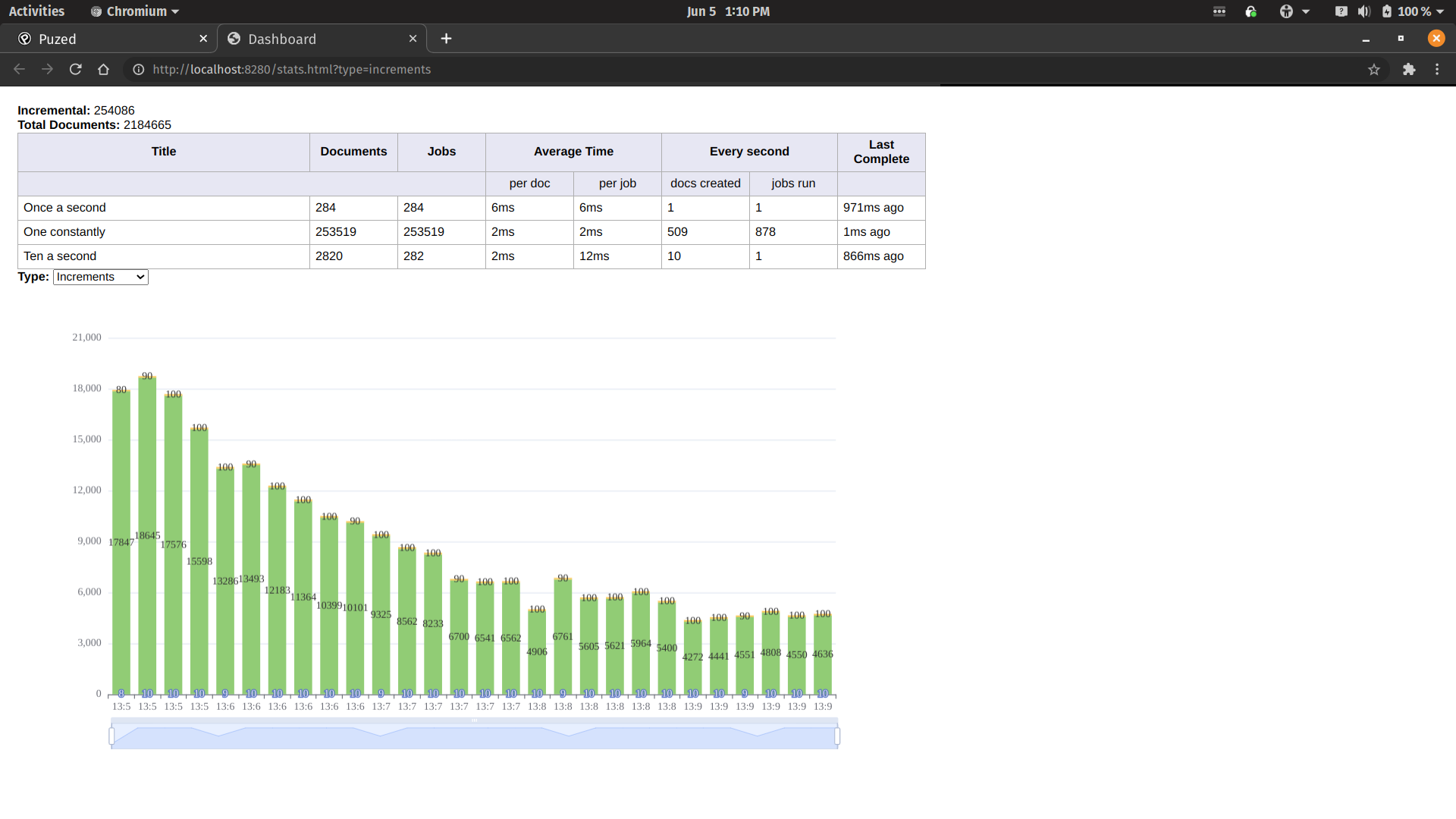
After a while drilling into the Puzed codebase, I decided to just trying the same metrics testing in a local Canhazdb instance instead.
To my surprise, Canhazdb was showing similar performance degregation.
Luckily, the first part of the stack I looked at, was the client. It didn't take too long to until I discovered a bug in the client. Everytime a message is sent to the server, it waits for a response. Once it receives a response, I wasn't cleaning up the callbacks. This was resulting in a huge array that could never empty.
3) Performance after fix
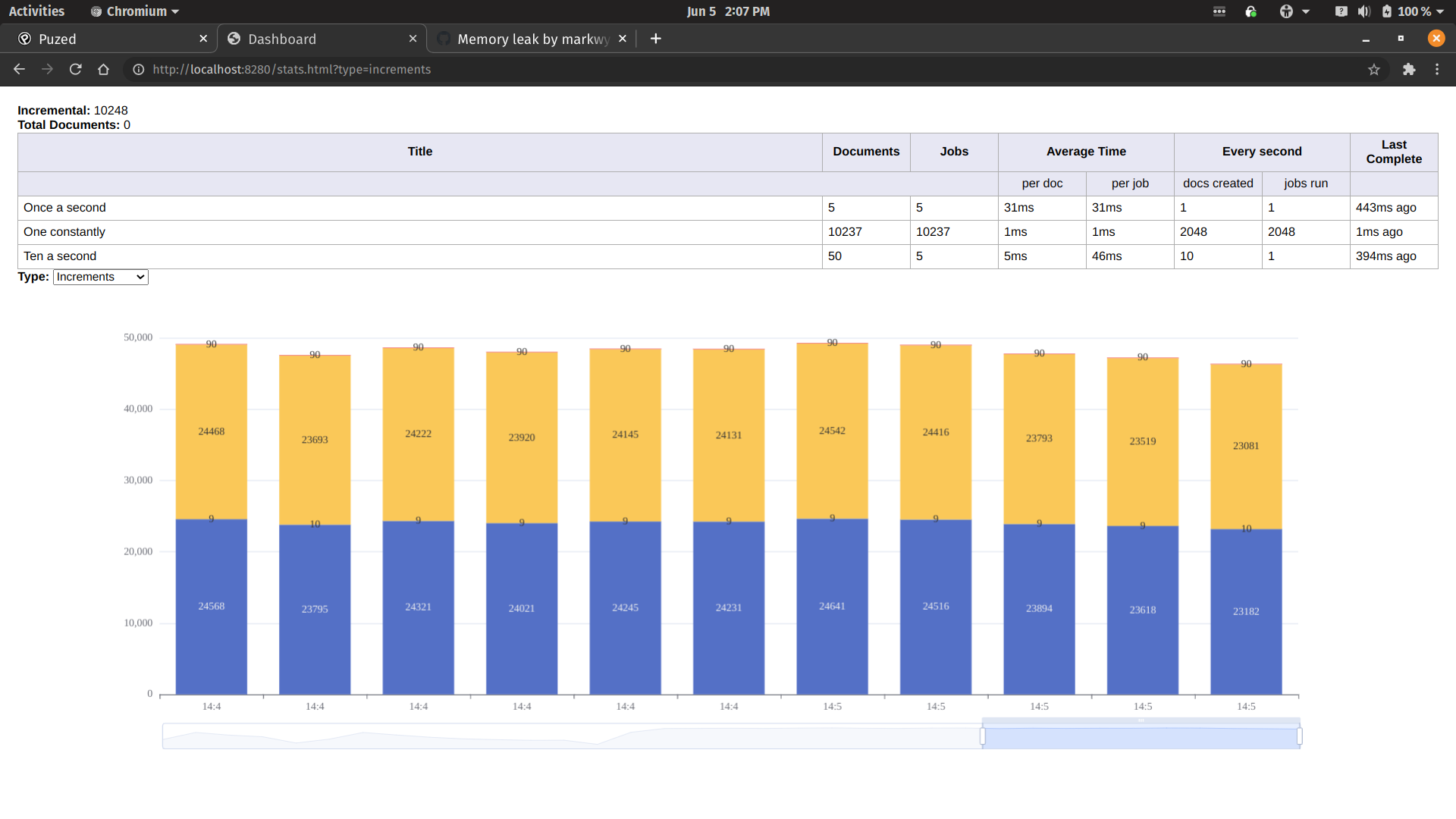
Finally, with the fix inplace, it looks like the performance is stable and consistent.
4) Puzed upgrade
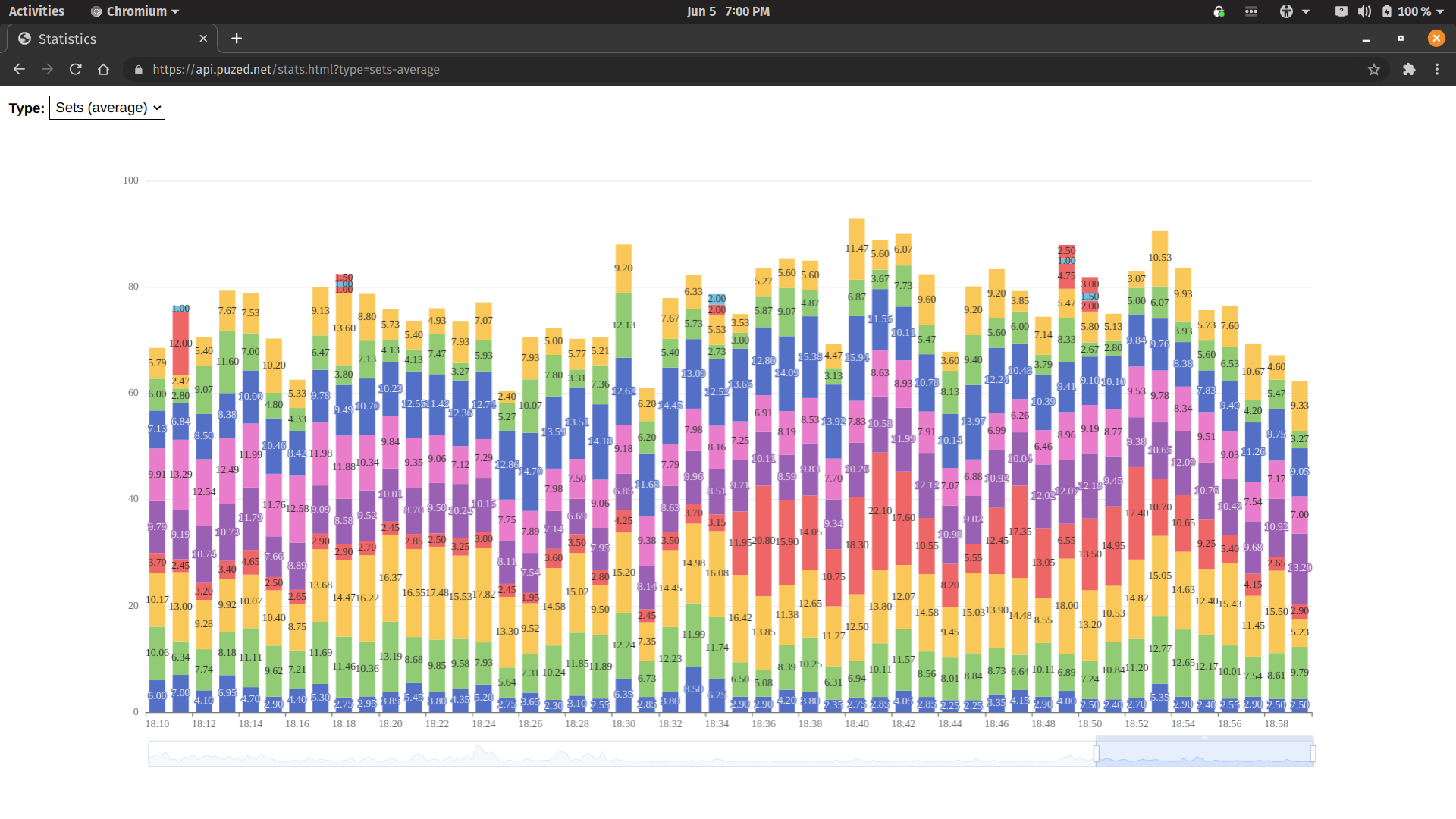
Finally, I upgraded the Canhazdb client dependency in the Puzed API server. This resulted, not only in much lower response times, but the beta server is now up and running for much longer than normal, along with consistent, linear response times.