- October 2021
- August 2021
- June 2021
- May 2021
- February 2021
ConflictsPublished by Mark Wylde on 2021-10-01
I've been slowly working through the last of the issues and feel like version 8 is very close to getting merged into master and released.
Conflicts
Conflict's have been completed, and will now attempt to resolve when a node recovers. The cleanup logic took a lot longer than I thought, but due to my own over complication of the strategy.
While resolving conflicts was as easy as letting all other nodes know about the resolution, and syncing with other nodes on startup, the deletion was trickier. We can only delete a conflict, once all other nodes have successfully received the conflict resolutions.
I'm sure there are improvements that can be made to the efficiency of the conflict implementation, but I'm happy that for now conflicts seem to be working well.
System Collections
The main system collections have been implemented:
system.collectionssystem.notifyssystem.lockssystem.nodes
The schema has changed a little from my initial idea, but the main information is still there.
It did identify one issue that I need to seed the system collections to the system.collections. I don't want to hard code this in, and would prefer each module is responsible for its own seeding.
But as there isn't the concept of "installing" the database, I might have to just check on every node start, if the collection has been added. It seems a little inefficient, but efficiency can be improved later.
Http Endpoints
The http server for issue #61 has been implemented, but I've only managed to write the get collections and get documents endpoints. It went pretty smoothly, and I hope the other endpoints will not take too long.
Required Certs
I've been trying to keep both TLS and unencrypted tcp to allow for easier development environments. But I'm becoming more uncomfortable with having this mix and match of tcp/http that can be secure or insecure. Plus, the NodeJS http2 library doesn't support none TLS communication.
Therefore, certs/TLS is now required for all instances running. You will not be able to connect to the http or TLS ports without full TLS validation.
The one exception will be the web UI client. That will use the same certs and be delivered over TLS, but it will not verify the client certificate. This means, you can access the web UI in your browser, but not the http api endpoints.
Next
Currently, I'm working on finishing the http endpoints, then will put a simple version check to ensure all nodes are on the same major version.
That will complete the last of the issues for the v8 release.
But before I merge and release, I need to properly update the documentation. Most importantly, I want to document the "canhazdb protocol".
Notify and LicensePublished by Mark Wylde on 2021-08-15
I've just finished implementing the notify logic. Logic has now been implemented to detect a temporary primary replica called isDocumentPrimaryReplica.
This can be used from an internal controller, when an action should be performed only once per internal method. For example:
- When you have
PATCHed 1 document that has 3 replicas, it should onlyNOTIFYonce. - When you need to return the effected documents (not replicas).
The current logic is:
function isDocumentPrimaryReplica (context, document) {
return document._replicatedNodes[0] === context.thisNode.name;
}
But ideally, this needs to also take into consideration if the actual primary replica is offline/unhealthy. I'll get to that later.
License change
The main project is deliberately licensed as AGPL-3, but I realised the client library was also licensed as AGPL-3 too.
That was not my intention. If you want to use the canhazdb client library, you do not have to release your entire app as AGPL-3. For example, if you run a canhazdb server cluster, and then build a separate app that talks to the server (either using the client library or your own), the project does not have to be licensed as AGPL-3.
Therefore, I have changed the canhazdb client license to be MIT.
Note, the license of the canhazdb server is still AGPL-3. The intention being, if you make any changes to the server or embed it into another product, the project should be licensed as AGPL-3 and source code released.
Next - Statistics
The last major feature for me to implement is the system.collections collection. I'll try to get that completed this week.
Once that's finished, I'm going to embed a very simple http server (without websocket notify support). Then finally, I can get the ha branch into master. Milestone reached!
High Availability UpdatePublished by Mark Wylde on 2021-08-11
Over the past few months I've not had the chance to work on canhazdb as much as I'd like, as my projects that use the first prototype (version 7) are still working really well.
But over the last week, I finally got some time to implement events, known as notify.
Notify
The syntax is still the same as before, but the protocol has now been updated to:
- Use the new lightweight byte syntax, as described in my last blog post
- Each
NOTIFY_ONcan only have oneNOTIFY_PATH
It's working really well, at least for post's. I still have some work to do to get put, patch, delete working. These are a little more tricky as one command can mutate multiple documents. With a post, it will only mutate one.
Count
The count command was very easy to implement. It's basically the same logic as a get, but instead of returning the documents, it returns just the number from each server.
Lock
Before I could implement the put, patch and delete commands we need locking.
I'm not entirely sure if this lock is needed. But because these commands trigger updates on multiple document replicas, I feel it's important that all replicas contain the same value.
So for now, when one of these three commands is sent, a lock will be placed on the collection while all documents are mutated, and then removed once complete.
I feel like when transactions are implemented further down the line, this could be removed, or at least change shape in some way.
Put, Patch, Delete
The put, patch and delete commands are similar to a post, but instead of choose three random servers to insert a document, we must go out to all servers and request updates.
With the built in $REPLICATION_FACTOR (currenly 3), if you have 3 or more servers, then each document will be inserted on each of the 3 servers.
So when one of these commands is issued externally, the server looks up every server in the cluster, and forwards the command.
The internal server needs to reply with the number of changes it made. However, it can't simply send how many document where updated. If we have 3 documents, each replicated 3 times, then our total change count would be 9.
Instead, the internal server will only respond with the documents it changed, where it was the first "online" server in the _replicatedNodes property.
System Statistics
The system.tables collection has not been implemented at all. I think it will be pretty easy to implement, as most of the logic from v7 can be carried over.
Reducing NoisePublished by Mark Wylde on 2021-06-15
I've been wanted to get high availability into canhazdb for quite a while now, but I had been unsure of exactly how I was going to implement it.
There's still some unknowns, but in general I feel I've got a good idea of where I want it to go.
This week I started a new branch, which is essentially a complete rewrite of the server.
Some major changes are in that branch:
No http(s)/ws(s) servers
When I wrote the first version, I kept juggling between the http(s) server, and the tcp servers. I decided for the rewrite, they really shouldn't have anything to do with each other.
I still want canhazdb to come with the option of a lightweight http server, but I'll put it in at the end, and it'll be abstracted out a lot more.
Protocol rewrite
The current stable version talks exclusively over JSON. So every time a node is asked to do something, it must receive the command in JSON and send a respones in JSON.
I still believe the biggest risk to the theory of canhazdb is network noise. Specially the noise of nodes that have no data to send back.
For example, when filtering on records (GET:/exampleCollection), a request is sent out to all nodes. In the current version is looks like this:
[10, {
"COMMAND": "GET",
"COLLECTION_ID": "exampleCollection",
"LIMIT": 10
}]
| n.b. the keys are shorted into numbers, but you get the idea.
In the latest version of tcpocket, I've reduced the protocol to be a pure buffer. At least, for the first 3 bytes.
The above turns into:
<Buffer>[0x01, 0x00, 0x09, ...optionalBufferSegments]
The first two bytes make up an Int16Array, which resolves to the correlation id (a number between 3 and 65535), to allow for request and responses. The third byte is a command (an Int8Array) which is a number between 2 and 255.
Look back at the GET example above, this will make the request a little smaller.
But I feel the main benefit comes from the response, especially for nodes with no information to return.
Currently if a node does not have any results to send, it returns:
[10, {
"STATUS": "200",
"DOCUMENTS": []
}]
With the new protocol, a node with no results to give can send:
<Buffer>[0x01, 0x00, 0x06]
This would mean for a filter that has to go out to a cluster of (for example) 10 nodes, if only 1 node has the document we are looking for, we have only wasted 9 bytes in the response.
There is much more to do on this, but I'm pretty happy so far. I have even noticed an improvement in the test speeds.
High Availability
With the rewrite, I've currently implemented the info, get, and post commands.
POST's
Performing a POST is one of the easiest commands on a database. The logic is basically, select $REPLICATION_FACTOR nodes at random (default 3), and insert the document.
Along with the document, each node is also told about all other nodes holding that replica.
GET's
When performing a GET, the request still gets forwarded to every node in the cluster. However, now, a node will only return a document, if they are the first healthy node in the documents replica list.
So far this is all working really well, and I'm happy with the performance (for now).
My next steps will be to implement locking again (as this is needed for PUT/PATCH/DELETE's), and then implement the rest of the commands.
EJDB vs SQLite
One thing that's been bothering me about EJDB is the restriction on indexing.
Every field is indexed in canhazdb, and EJDB supports really good and fast indexing. However, you can only use them under certain conditions.
For this reason I'm considering testing SQLite again, but using a different strategy from last time. I'm concerned though that the overhead of a relational database engine will give a considerable performance loss. But I think it's worth a test.
Failing that, I might raise an issue with the EJDB author to find out any better solution for filtering on multiple indexes.
Performance BugPublished by Mark Wylde on 2021-06-05
For the last few months Puzed, which uses Canhazdb, has been slowing down as time passes. This bug would cause an instance to crash at least once a day.
I had tried on and off to debug this over the past six months, but my focus was mainly on the Puzed project. This is because Puzed has so much logic, scheduled jobs, healthchecks and more. I was certain there was a leak somewhere in that code.
But as I mentioned in my previous blog post, I wanted to stress test Canhazdb on it's own to see what it's limitations are.
Starting on Puzed, I added some metrics monitoring to the project. This resulted in the following:
1) Puzed Performance
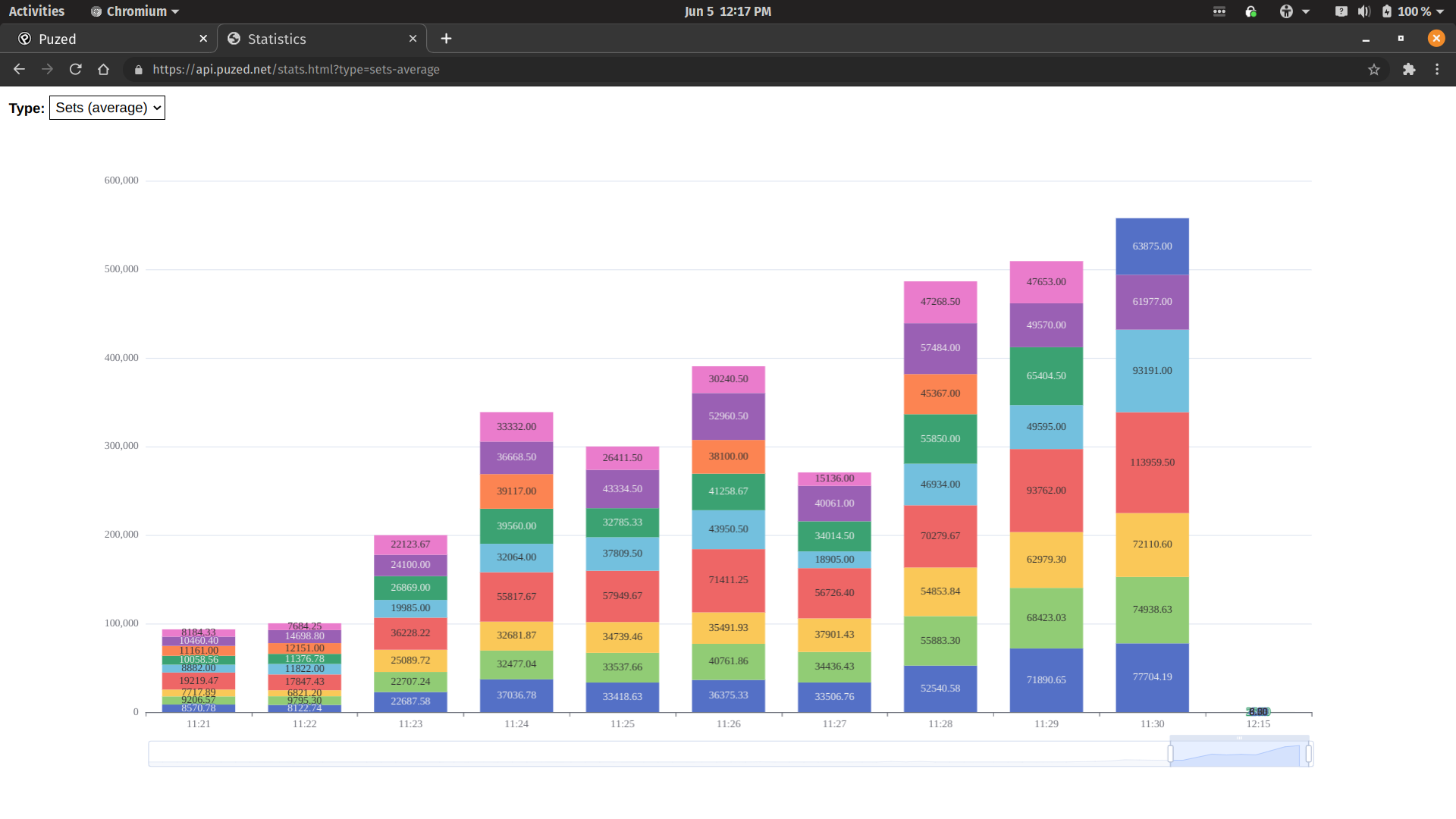
The above is a snapshot showing the different type of database requests, along with the average time (in milliseconds) it took to complete the request.
You can see, it gradually takes longer and longer to perform essentially the same number of queries.
2) Canhazdb Performance
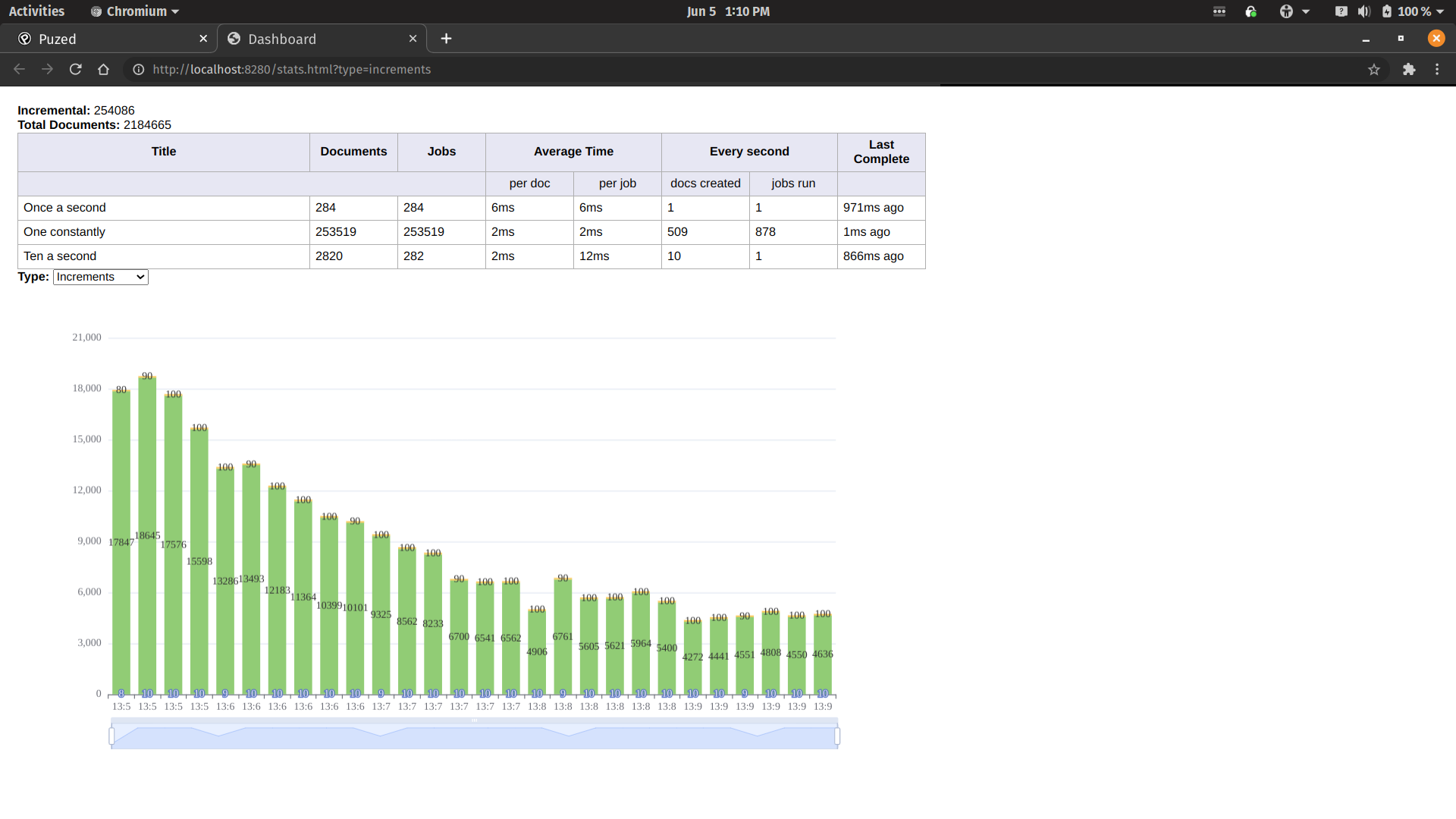
After a while drilling into the Puzed codebase, I decided to just trying the same metrics testing in a local Canhazdb instance instead.
To my surprise, Canhazdb was showing similar performance degregation.
Luckily, the first part of the stack I looked at, was the client. It didn't take too long to until I discovered a bug in the client. Everytime a message is sent to the server, it waits for a response. Once it receives a response, I wasn't cleaning up the callbacks. This was resulting in a huge array that could never empty.
3) Performance after fix
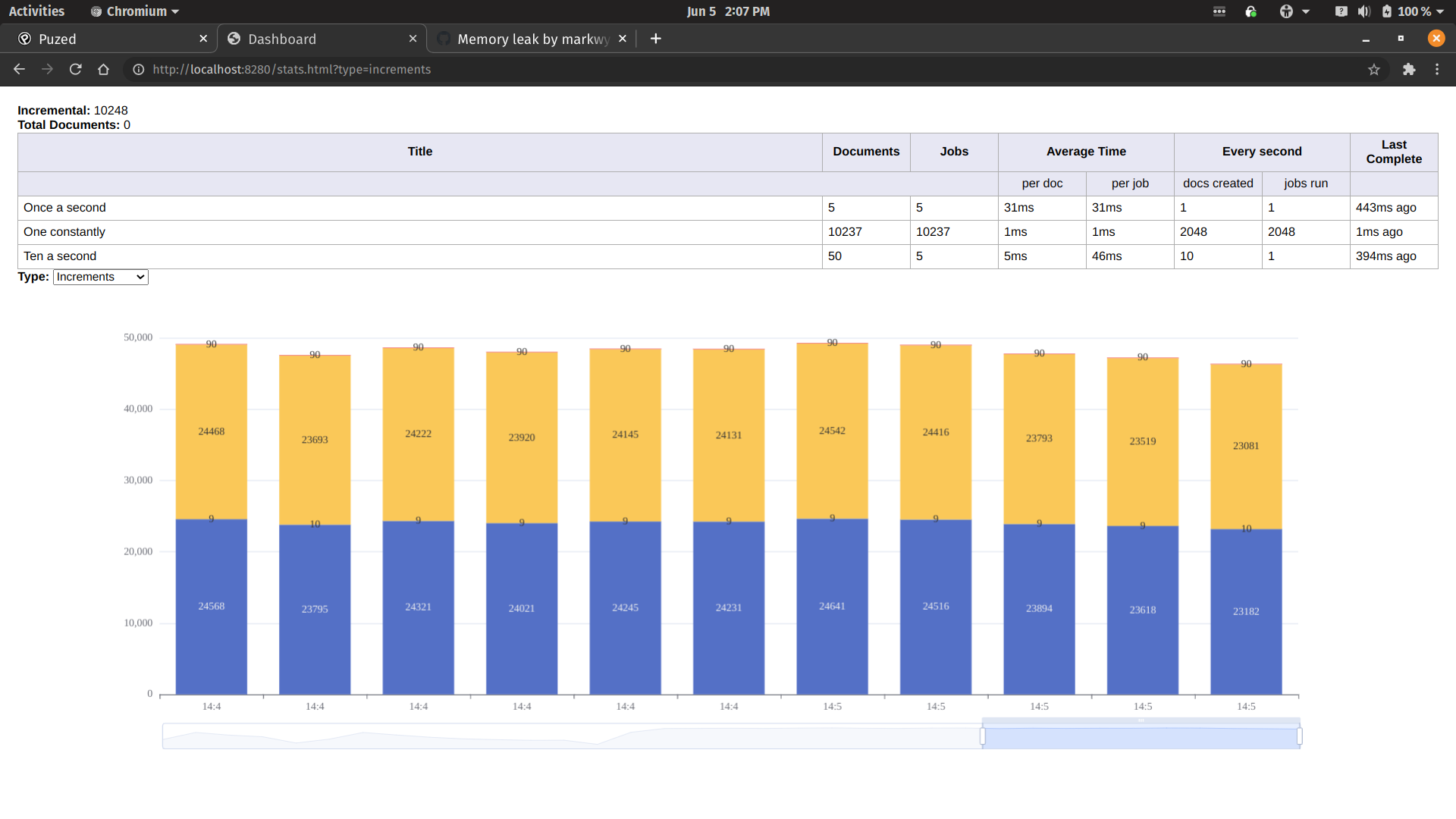
Finally, with the fix inplace, it looks like the performance is stable and consistent.
4) Puzed upgrade
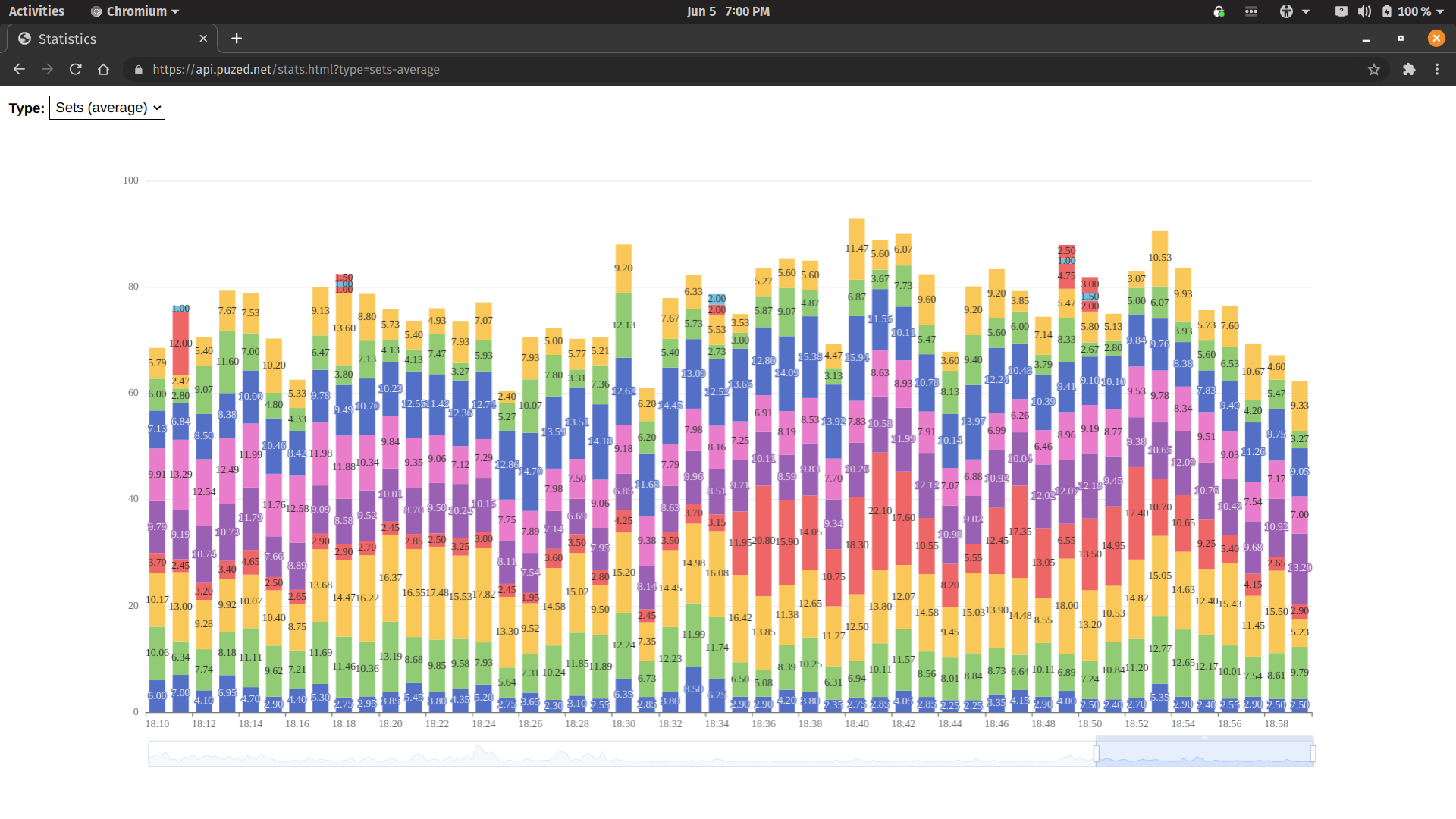
Finally, I upgraded the Canhazdb client dependency in the Puzed API server. This resulted, not only in much lower response times, but the beta server is now up and running for much longer than normal, along with consistent, linear response times.